还在为搜图不够精准、推荐不够懂你而烦恼?
360 人工智能研究院发布的全新 FG-CLIP(Fine Grained CLIP)模型,让 AI 也能像“老司机”一样,练就“眼观六路”的本领。
有了 FG-CLIP,它能瞬间辨别 “穿着浅蓝色夹克的男人” vs “穿着草绿色夹克男人”、“陶瓷茶杯”与“玻璃茶杯”的细微差别,图片被裁切也不怕,照样精准识别目标,甚至连那张藏在小狗身后、位于画面角落的浅棕色木凳子,它也不会放过。
这一突破性成果已被 AI 顶会 ICML 2025 接收,并已开源。
- 开源地址:https://github.com/360CVGroup/FG-CLIP
- 论文地址:https://www.arxiv.org/abs/2505.05071
从 OpenAI 2020 年发布 CLIP 模型至今,图文跨模态技术已发展 5 年,广泛应用于互联网搜广推、办公检索等领域。 然而,受限于基于图文整体特征对齐的对比学习原理,初代 CLIP 模型因其基于图文整体特征进行对齐的对比学习原理,一直存在图文特征对齐粒度粗,无法实现图文细粒度理解的核心难题,制约了它在搜索、推荐、识别中的应用效果。
针对这一核心难点,360 人工智能研究院冷大炜博士团队基于前期在多模态理解与多模态生成领域的工作积累,研发了新一代的图文跨模态模型 FG-CLIP,攻克了显式双塔结构下图文信息的细粒度对齐难题。
FG-CLIP 亮点提炼:
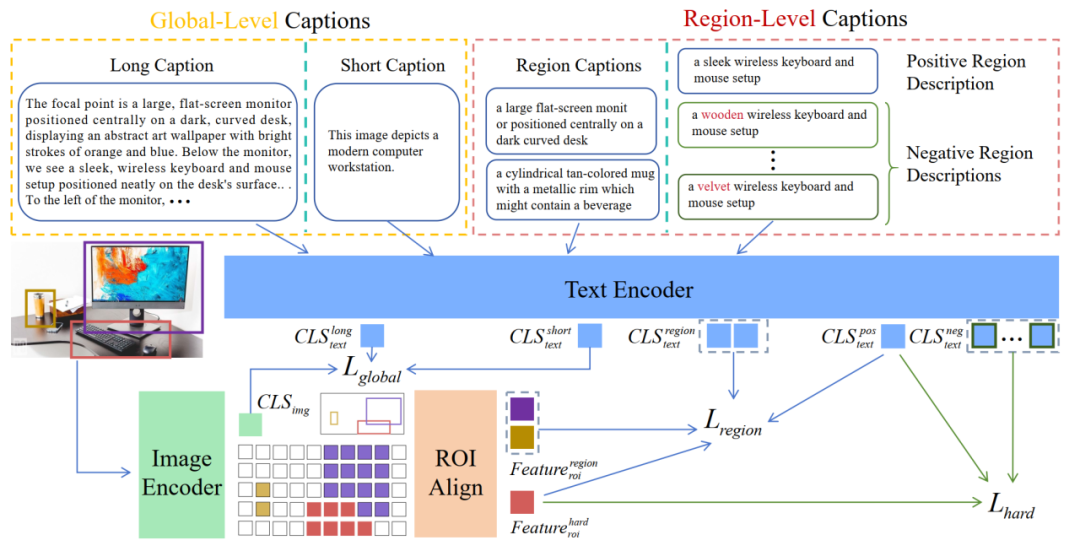
显式双塔结构解耦: 突破传统 CLIP 架构限制,首次在显式双塔结构下实现图文细粒度对齐。
双阶段训练策略: 采用全局对比学习+区域对比学习,由粗到精,让模型既能把握全局,又能洞察细节。
难细粒度负样本学习: 创新构建难负样本,有效提升模型对细微语义差异的辨别能力。
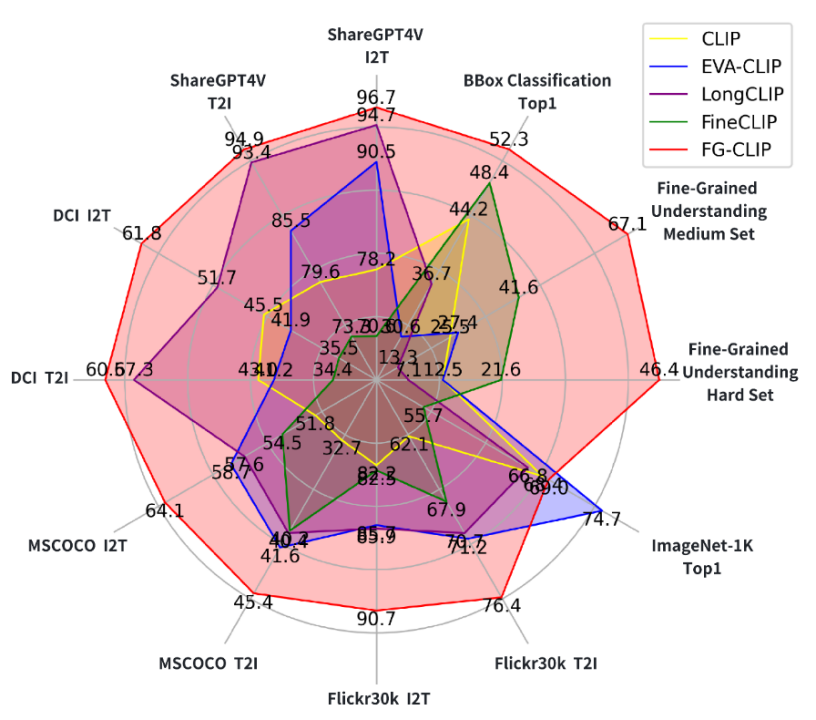
跨模态对齐能力提升显著:在 FG-OVD 等评测中,全面超越 CLIP/FineCLIP 等对比模型,展现出更强的局部识别与细节感知能力。
全开源发布:模型权重、训练代码、数据集全部开放,推动跨模态研究真正从实验室走向产业化落地。
今天聊聊“图文跨模态模型”,一个能在语义层面实现图像信息和文字信息之间进行相互转换的“翻译官”。和能直接陪你聊天的 DeepSeek/豆包模型不同,这位 “翻译官” 更像幕后的工程师 —— 你看不到它,但每天都在享受它的服务:找图更快、推荐更准、办公更省心…… 它就像科技产品的 “隐形默契搭档”,让体验更懂你的需求。大家平时刷到的那些“神操作” 其实都离不开它:比如用手机输入文字就能生成动漫插画、风景海报的绘图软件(Stable Diffusion、可图),还有能把 “小猫追蝴蝶” 的文字描述变成动态视频的工具(Sora、即梦),背后都需要这位 “翻译官” 先把文字和图片的信息 “翻译” 成机器能懂的语言,让两者 “对上频道”。不只是这些有趣的应用,咱们日常生活里处处都有它的影子:- 上网搜索:当你搜“海边日落风景图” 时,它能帮你精准找到匹配文字描述的图片;
- 刷短视频 / 逛购物 App:你看到的美食推荐、衣服穿搭内容,其实是它根据你的浏览习惯,把“你可能喜欢” 的文字标签和图片 / 视频 “牵线搭桥”;
- 办公软件:比如用智能文档问“如何做年度总结”,它能快速从海量资料里找到图文结合的答案;
- 监控系统:商场、街道的摄像头能自动识别“异常行为”,也是它在帮忙 “看图说话”,快速判断画面里的情况。
视觉与语言的跨模态理解是大模型时代众多关键技术与业务应用的核心基石,如多模态大语言模型,图像生成模型,视频生成模型等,都要用到图文跨模态模型进行视觉信息和/或文本信息的编码和模态对齐。与直接能与终端用户交流对话的智能问答不同的是,图文跨模态模型不被普通用户所见,但大家每天可以通过各种产品如互联网搜索,商品推荐,文档办公等来感受图文跨模态模型给我们的生活带来的上述现实便利。当前普遍使用的图文跨模态模型如 OpenAI CLIP,EVA-CLIP 等,仍是基于第一代的整体图文对比学习算法训练得到,它们擅长捕捉全局信息,却难以分辨物体的细微属性差异,在处理细粒度视觉理解时面临非常大的挑战。例如,区分“一只黑色的狗”与“一只深棕色的狗”,或识别“陶瓷茶杯”与“玻璃茶杯”的材质差异,往往会让模型陷入困惑。攻克图文跨模态模型存在的上述“近视”问题,提升模型对图文局部细节的深度理解,是我们关注的一个重要研究课题。视力大挑战:找一找右边的哪句话,正确描述了左边图像里的内容?答案在最右侧。可以发现,4 个常用模型:CLIP、EVACLIP、SIGLIP、FINE-CLIP 基于左侧图片选出的最匹配的文本描述是:A blue dog with a white colored head。显然这个描述是错误的,这些模型因为“近视”问题忽略了目标的属性匹配。正确答案是由今天我们要介绍的新模型 FG-CLIP 选出的 A light brown wood stool(一个浅棕色的木凳子),注意看,这个木凳子位于画面的中央偏右,悄悄隐藏在狗狗的身后。与现有模型相比,FG-CLIP 有效解决了前述的“近视”问题,在关键的长文本理解+细粒度比对上实现了大幅的双突破。FG-CLIP 在细粒度理解、开放词汇对象检测、长短文本图文检索以及通用多模态基准测试等下游任务中均显著优于原始 CLIP 和其他最先进方法。FG-CLIP 在传统双编码器架构基础上采用两阶段训练策略,有效提升了视觉语言模型的细粒度理解能力。首阶段通过全局对比学习实现图文表征的初步对齐;次阶段引入区域对比学习与难细粒度负样本学习,利用区域-文本标注数据深化模型对视觉细节的感知能力,从而在保持全局语义理解的同时实现了对局部特征的精准捕捉。全局对比学习通过整合多模态大模型生成的长描述,显著增强了模型的细粒度理解能力。这种方法不仅生成了内容丰富的长描述,还提供了更完整的上下文信息和更精准的细节描述。通过引入长描述,模型得以在全局层面感知和匹配语义细节,从而大幅提升了其上下文理解能力。同时,FG-CLIP 保留了原有的短描述-图像对齐机制,使长短描述形成互补。这种双轨并行的策略使模型既能从长描述中获取复杂的语义信息,又能从短描述中把握核心概念,从而全面提升了模型对视觉信息的理解和处理能力。局部对比学习通过精准对齐图像局部区域与对应文本描述,实现细粒度的视觉-语言关联。具体而言,他们首先运用 RoIAlign 从图像中精确提取区域特征,继而对每个检测区域施加平均池化操作,获取一组富有代表性的区域级视觉表征。这些局部特征随后与预先构建的细粒度文本描述进行对比学习,促使模型建立区域视觉内容与文本语义之间的精确映射关系,从而掌握更为细致的跨模态对齐能力。