
在4月27日召开的中关村论坛通用人工智能平行论坛上,人大系初创公司智子引擎隆重发布全新的多模态大模型Awaker 1.0,向AGI迈出至关重要的一步。
相对于智子引擎前代的ChatImg序列模型,Awaker 1.0采用全新的MOE架构并具备自主更新能力,是业界首个实现「真正」自主更新的多模态大模型。在视觉生成方面,Awaker 1.0采用完全自研的视频生成底座VDT,在写真视频生成上取得好于Sora的效果,打破大模型 「最后一公里」落地难的困境。
Awaker 1.0是一个将视觉理解与视觉生成进行超级融合的多模态大模型。在理解侧,Awaker 1.0与数字世界和现实世界进行交互,在执行任务的过程中将场景行为数据反哺给模型,以实现持续更新与训练;在生成侧,Awaker 1.0可以生成高质量的多模态内容,对现实世界进行模拟,为理解侧模型提供更多的训练数据。尤其重要的是,因为具备「真正」的自主更新能力,Awaker 1.0适用于更广泛的行业场景,能够解决更复杂的实际任务,比如AI Agent、具身智能、综合治理、安防巡检等。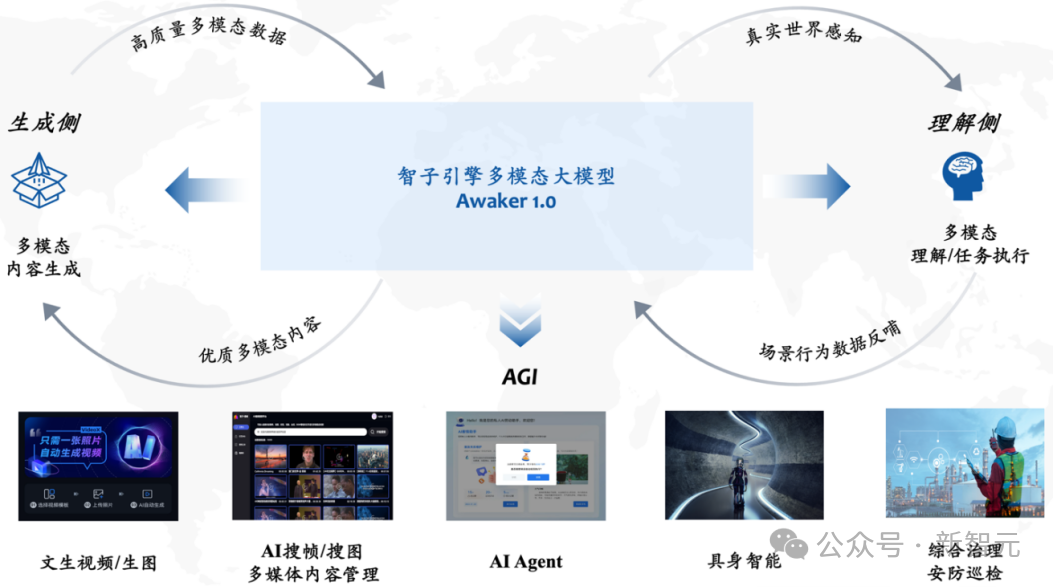
Awaker的MOE基座模型
在理解侧,Awaker 1.0的基座模型主要解决了多模态多任务预训练存在严重冲突的问题。受益于精心设计的多任务MOE架构,Awaker 1.0的基座模型既能继承智子引擎前代多模态大模型ChatImg的基础能力,还能学习各个多模态任务所需的独特能力。相对于前代多模态大模型ChatImg,Awaker 1.0的基座模型能力在多个任务上都有了大幅提升。鉴于主流的多模态评测榜单存在评测数据泄露的问题,我们采取严格的标准构建自有的评测集,其中大部分的测试图片来自个人的手机相册。在该多模态评测集上,我们对Awaker 1.0和国内外最先进的三个多模态大模型进行公平的人工评测,详细的评测结果如下表所示。注意到GPT-4V和Intern-VL并不直接支持检测任务,它们的检测结果是通过要求模型使用语言描述物体方位得到的。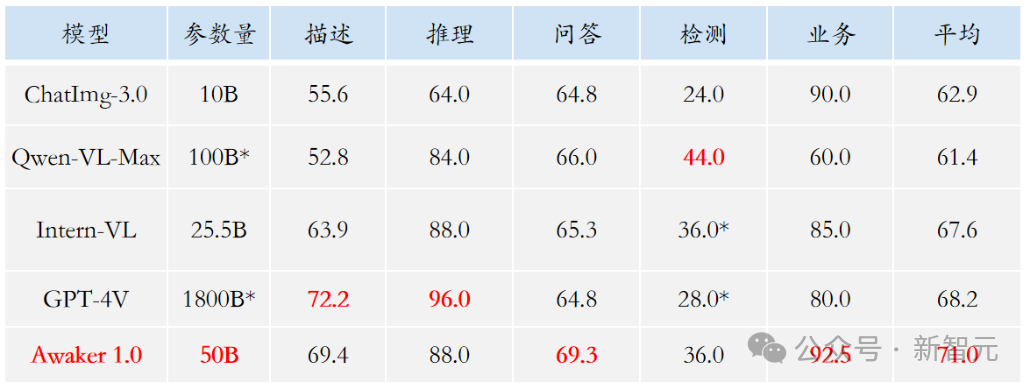
可以看到,Awaker 1.0的基座模型在视觉问答和业务应用任务上超过了GPT-4V、Qwen-VL-Max和Intern-VL,同时它在描述、推理和检测任务上也达到了次好的效果。总体而言,Awaker 1.0的平均得分超过国内外最先进的三个模型,验证了多任务MOE架构的有效性。下面是几个具体的对比分析例子。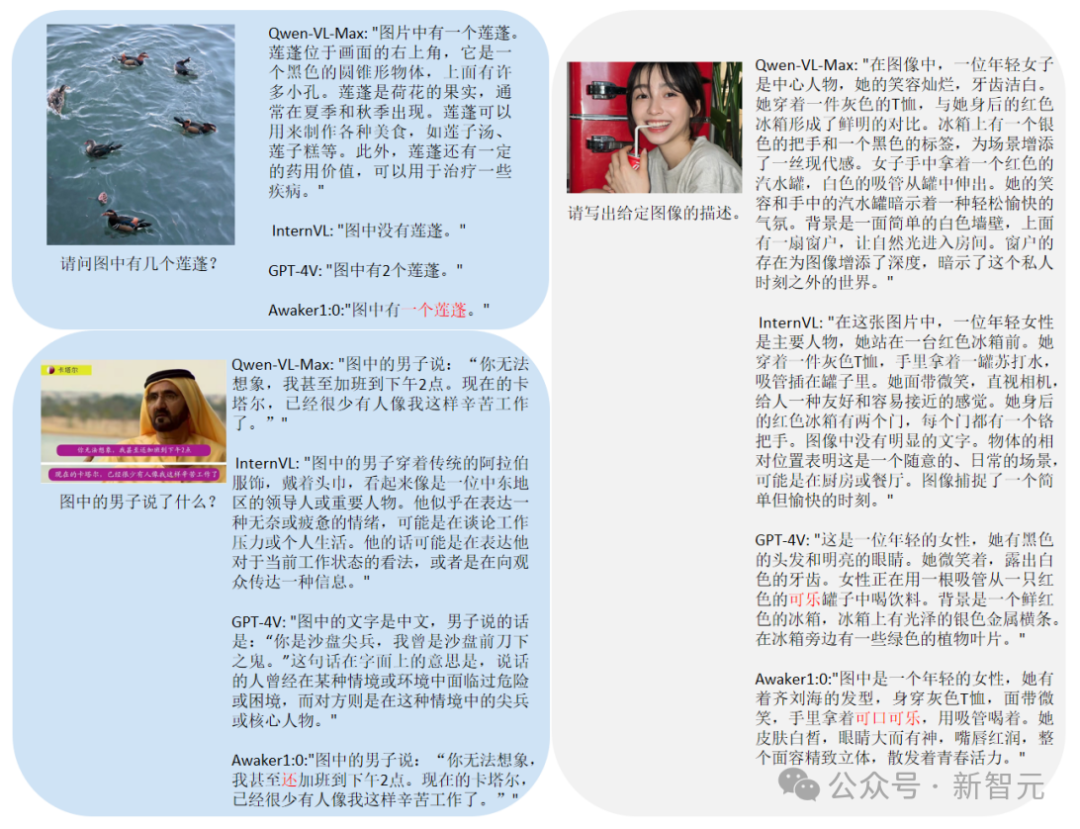
从这些对比例子可以看到,在计数和OCR问题上,Awaker 1.0能正确地给出答案,而其它三个模型均回答错误(或部分错误)。在详细描述任务上,Qwen-VL-Max比较容易出现幻觉,Intern-VL能够准确地描述图片的内容但在某些细节上不够准确和具体。GPT-4V和Awaker 1.0不但能够详细地描述图片的内容,而且能够准确地识别出图片中的细节,如图中展示的可口可乐。
多模态大模型与具身智能的结合是非常自然的,因为多模态大模型所具有的视觉理解能力可以天然与具身智能的摄像头进行结合。在人工智能领域,「多模态大模型+具身智能」甚至被认为是实现通用人工智能(AGI)的可行路径。一方面,人们期望具身智能拥有适应性,即智能体能够通过持续学习来适应不断变化的应用环境,既能在已知多模态任务上越做越好,也能快速适应未知的多模态任务。另一方面,人们还期望具身智能具有真正的创造性,希望它通过对环境的自主探索,能够发现新的策略和解决方案,并探索人工智能的能力边界。通过将多模态大模型用作具身智能的「大脑」,我们有可能大幅地提升具身智能的适应性和创造性,从而最终接近AGI的门槛(甚至实现AGI)。但是,现有的多模态大模型都存在两个明显的问题:一是模型的迭代更新周期长,需要大量的人力和财力投入;二是模型的训练数据都源自现有的数据,模型不能持续获得大量的新知识。虽然通过RAG和长上下文的方式也可以注入持续出现的新知识,但是多模态大模型本身并没有学习到这些新知识,同时这两种补救方式还会带来额外的问题。总之,目前的多模态大模型在实际应用场景中均不具备很强的适应性,更不具备创造性,导致在行业落地时总是出现各种各样的困难。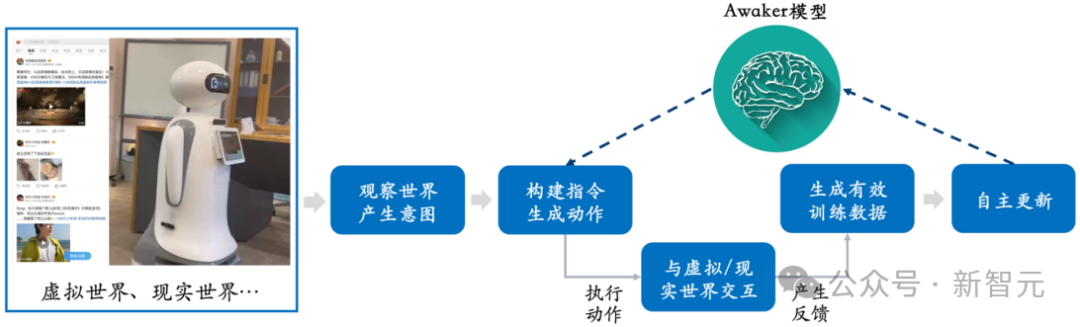
智子引擎此次发布的Awaker 1.0,是世界上首个具有自主更新机制的多模态大模型,可以用作具身智能的「大脑」。Awaker 1.0的自主更新机制,包含三大关键技术:数据主动生成、模型反思评估、模型连续更新。区别于所有其它多模态大模型,Awaker 1.0是「活」的,它的参数可以实时持续地更新。从上方的框架图中可以看出,Awaker 1.0能够与各种智能设备结合,通过智能设备观察世界,产生动作意图,并自动构建指令控制智能设备完成各种动作。智能设备在完成各种动作后会自动产生各种反馈,Awaker 1.0能够从这些动作和反馈中获取有效的训练数据进行持续的自我更新,不断强化模型的各种能力。以新知识注入为例,Awaker 1.0能够不断地在互联网上学习最新的新闻信息,并结合新学习到的新闻信息回答各种复杂问题。不同于RAG和长上下文的传统方式,Awaker 1.0能真正学到新知识并「记忆」在模型的参数上。
从上述例子可以看到,在连续三天的自我更新中,Awaker 1.0每天都能学习当天的新闻信息,并在回答问题时准确地说出对应信息。同时,Awaker 1.0在连续学习的过程中并不会遗忘学过的知识,例如智界S7的知识在2天后仍然被Awaker 1.0记住或理解。Awaker 1.0还能够与各种智能设备结合,实现云边协同。Awaker 1.0作为「大脑」部署在云端,控制各种边端智能设备执行各项任务。边端智能设备执行各项任务时获得的反馈又会源源不断地传回给Awaker 1.0,让它持续地获得训练数据,不断进行自我更新。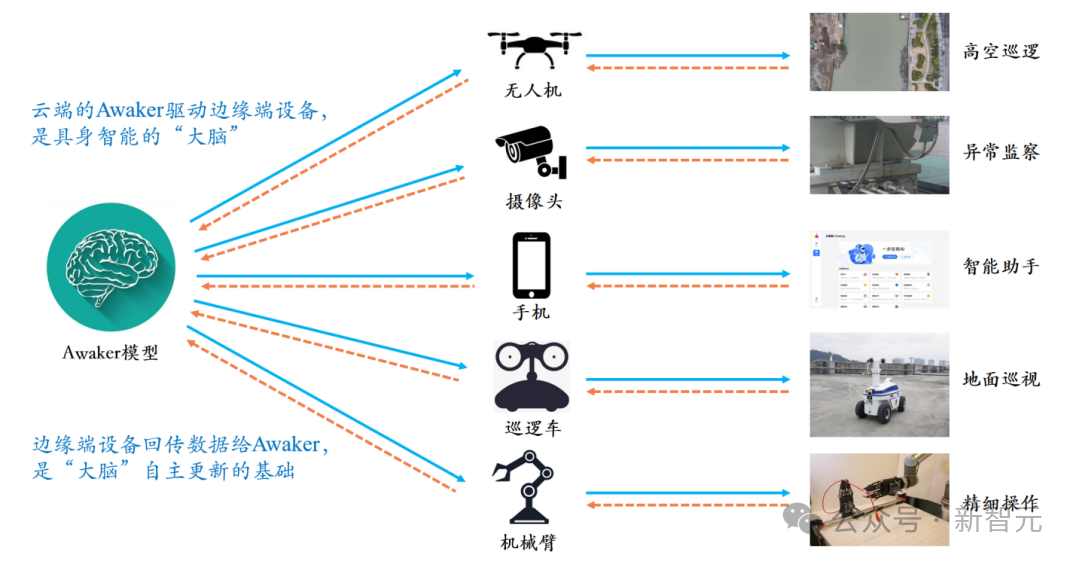
上一篇:
【国际视野】全球首个自主进化多模态MoE震撼登场!写真视频击败Sora,人大系团队自研底座VDT



