


【新智元导读】贾佳亚团队提出VLM模型Mini-Gemini,堪比GPT-4+DALL-E 3王炸组合,一上线就刷爆了多模态任务榜单!读得懂梗图,做得了学术,用代码就能复现数学函数图。
刷爆多模态任务榜单,超强视觉语言模型Mini-Gemini来了!
效果堪称是开源社区版的GPT-4+DALL-E 3王炸组合。
不仅如此,这款由港中文终身教授贾佳亚团队提出的多模态模型,一经发布便登上了PaperWithCode热榜。

Demo地址: http://103.170.5.190:7860/
论文地址:https://arxiv.org/pdf/2403.18814.pdf
具体来说,Mini-Gemini提供了2B小杯到34B的超大杯的不同选择。
凭借超强的图文理解力,Mini-Gemini在多个指标上,直接媲美Gemini Pro,GPT-4V。

目前,研究团队将Mini-Gemini的代码、模型、数据全部开源。
更有意思的是,超会玩梗的Mini-Gemini线上Demo已经发布,人人皆可上手试玩。
Mini-Gemini Demo放出后受到广大网友关注,一番「尝鲜」后,有人认为:Mini-Gemini跟商业模型差不了多少!
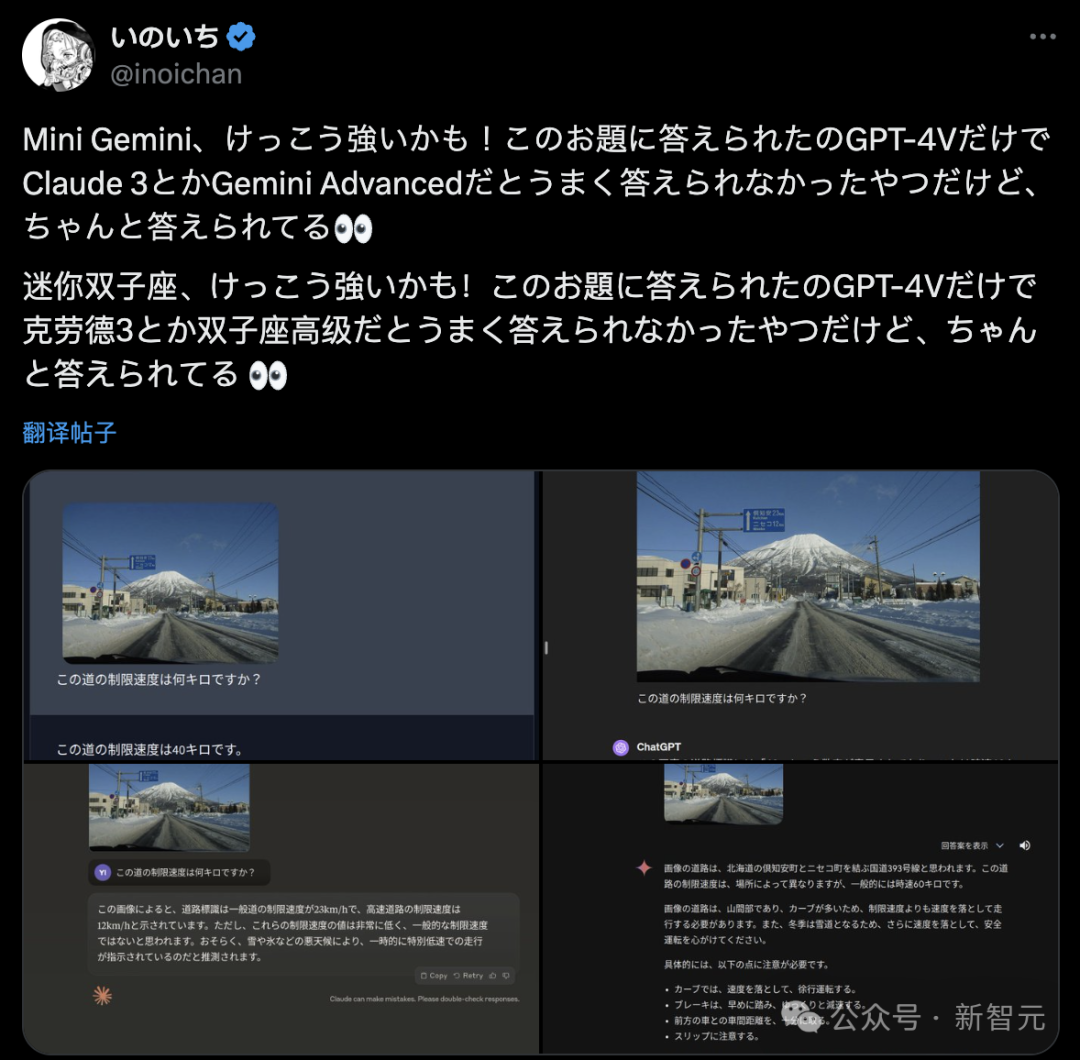
为何这么说?
图片理解天花板
当前,绝大多数多模态模型仅支持低分辨率图像输入和文字输出。
而在实际场景中,许多任务都需要对高清图像进行解析,并用图像的形式进行展现。
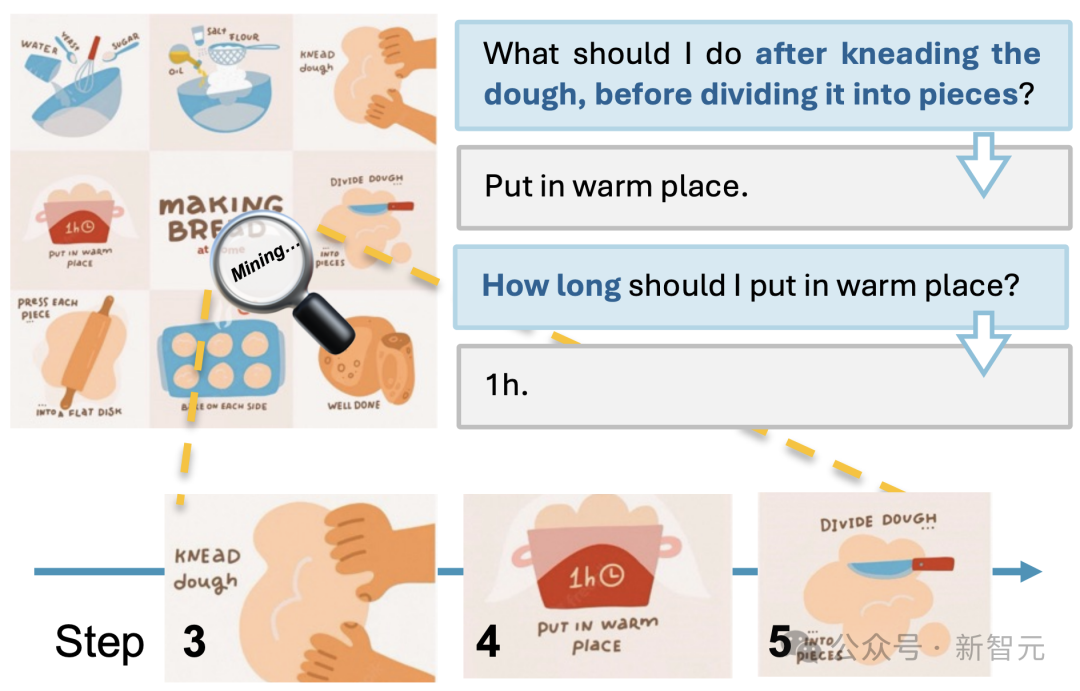
举个例子,Mini-Gemini能够看懂面包九宫格图片教程,并进行手把手教学。
拍一张苹果店Mac电脑信息图,Mini-Gemini能够将两种尺寸的Mac不同参数进行对比。
有网友看过后表示,「妈妈再也不用担心我的生活了」。

更重要的是,Mini-Gemini在保留超强的图像理解和推理能力的同时,还解锁了图像的生成能力,就如同ChatGPT和生成模型的结合。
下面,让我们通过几个例子来更直观地感受这种能力:
推理再生成,更精准了
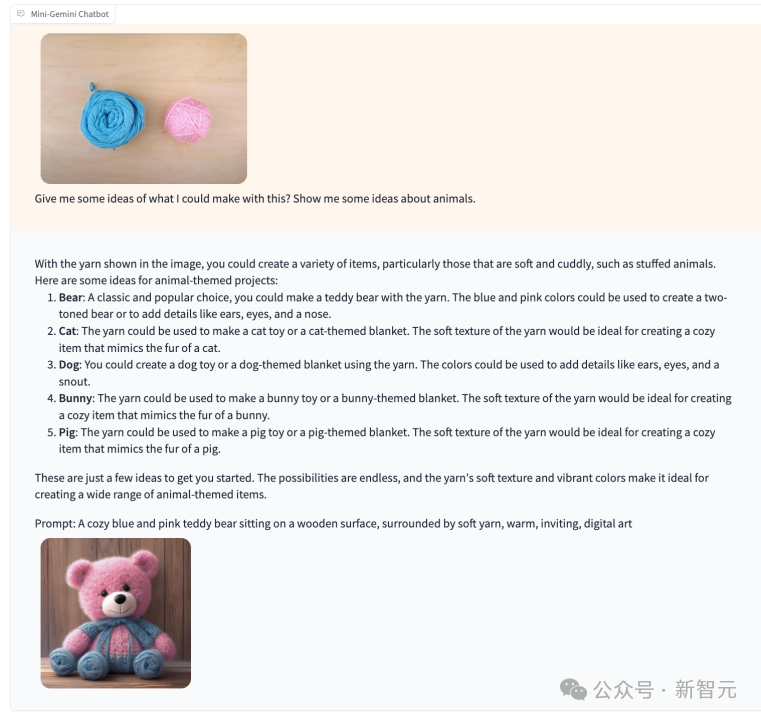
还记得谷歌Gemini的官方演示视频么?
当用户给出两个毛线团并问出能用它们做什么时,Gemini可以识别出图片内容并给出相应的建议。



当我们把相似的输入给到Mini-Gemini,它会怎么回答呢?

可以发现,Mini-Gemini也可以识别出图片中的元素,并且合理地建议,同时生成了一只对应的毛线小熊。
通过一些抽象的多模态指令来让模型给出推理,并生成合适的图片,这个操作就很像是ChatGPT和DALLE3的联动了!
接下来让Mini-Gemini做自己最擅长的推理和图片理解,看看它表现。
比如,理解图片中的矛盾点并举一反三。
输入冰川中的仙人掌,它会解释其中的矛盾并生成一张热带雨林中北极熊的图片:
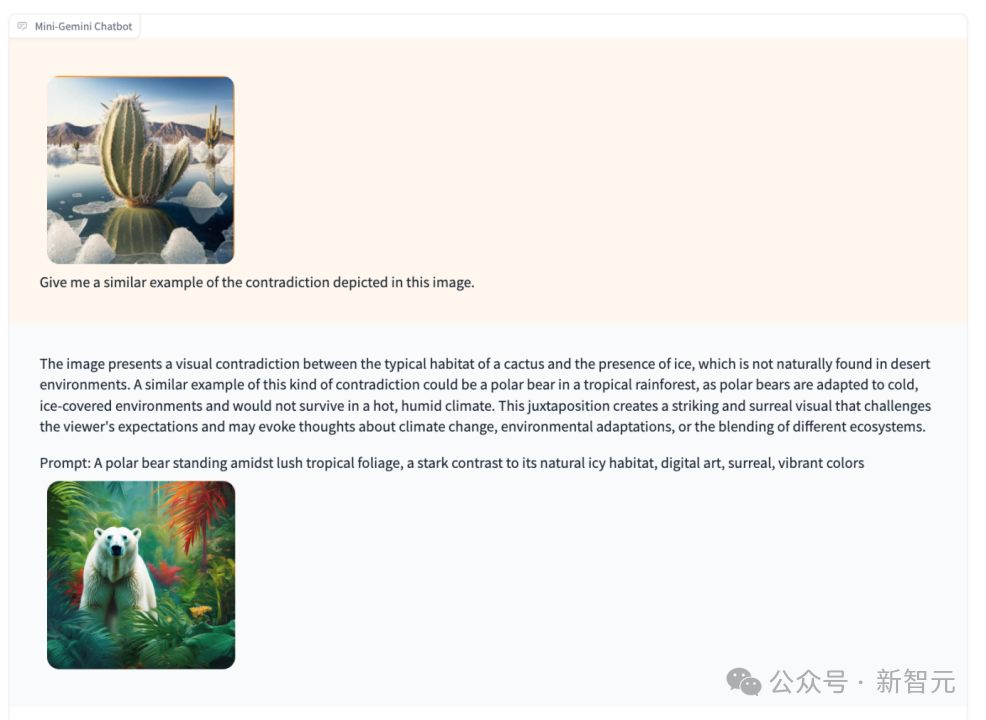
图片呈现了仙人掌的典型栖息地与冰的存在之间的视觉矛盾,因为在沙漠环境中自然不会出现冰。
Mini-Gemini正是理解了这种矛盾点,才生成了一张北极熊出现在热带雨林的图片。
